排列组合大概是数学中学习者年龄跨度最大的部分之一了吧。从学奥数的小学生们到即将参加高考的我们,都无不被排列组合问题所困扰。为什么几乎没有抽象定义、基本逻辑符合直觉的排列组合能常常难倒我们呢?我想,原因可能就是它定义地过于简单了,有一些我们所认为的「常识」,并没有经过仔细的审视。这样最终会导致我们认为简单的「常识」之间没有联系,总结的解法也常常局限于例子。当条件稍微有些改变时,我们就常常不知道该怎样更改普遍的解题策略使其适应了。
首先来明确最基础的定义。排列和组合都是什么意思?它们有什么区别?这两个概念其实都来源于数学中的计数法。所谓计数法,从字面和常识去理解就能猜到它指的是求给定集合中元素个数的方法。很容易想到,要做到计数,我们就要遍历集合中的全部元素。这就是最基本的解法,也是排列组合这些解法的本质。遍历强调的是不能重复也不能遗漏,而这就是所有解法要遵循的基本原则了。这些虽然抽象,却应该作为思考的出发点。只有这样,我们才能够把握各种看似不相关的事物的联系。
现在开始讨论具体的例子。考虑一个集合\(A= \begin{Bmatrix} a, b, c \end{Bmatrix}\) ,我们现在要进行计数。不过对这个集合计数有些无聊,你可以直接数出来它的元素个数是3. 我们现在定义出一个新的集合\(B\) ,使集合\(B\) 的元素等于集合\(A\) 中任意两个元素的排列。等一下,我们为什么说排列而不是组合?这就引出了前面那两个问题的答案。排列是「关心顺序」的,而组合是「不关心顺序」的。也就是说,如果认为\(ab = ba\) 则是组合,否则是排列。现在,我们想要问集合\(B\) 中有多少个元素。这当然也就是在问,\(a,b,c\) 中任意选出两个有多少种不同的排列,而且我们把顺序不同也算作不同。
接下来的问题就是如何解答了。仔细回想你数集合\(A\) 中元素个数的过程,你会发现自己是按照一定的顺序数的。这是什么意思?我们可以用这个式子表示:\(a \rightarrow b \rightarrow c\) . 也就是你用有向的箭头把集合中的元素连接起来,第一个计数为1,此后顺着箭头遍历,每遇到新的元素就把计数加上1,直到最后没有箭头可往下遍历为止。这就是最基本的遍历方法了。而它给我们的思路就是:要在元素之间建立连接。集合中元素建立连接后形成的,我们称之为「图」。在数学中还有专门研究图的部分,就叫做「图论」。我们是这样想的:字母就是图中的节点,而箭头就是有向线段,它把节点连接起来。每个节点都是计数过程中的一个状态,而有向线段则提供这个状态转到下一个状态的方式,也就是在计数器上加1.
也许你想说这样的解法效率太低了,但我们不妨将它作为思考的起点,在这个基础上尝试优化。我们首先要写出集合\(B\) 的元素。不过我们要怎么写呢?我们不能看着集合\(A\) 并毫无规律地写下集合\(B\) ,因为那样既有可能重复,而且更容易遗漏。这就违背了上面所说的两个原则了。一个好的方法是通过遍历给定集合\(A\) 来写出集合\(B\) . 我们直接按照刚才的\(a \rightarrow b \rightarrow c\) 遍历。注意到集合\(B\) 的定义是:随机按照顺序选择\(A\) 中两个元素,所有可能的情况。我们就在每次遍历到新的元素时把该元素作为第一个,然后重新开始遍历一遍作为第二个。这样就能确保不重复也不遗漏了。结果如下: \[
\begin{Bmatrix}
aa,ab,ac,ba,bb,bc,ca,cb,cc
\end{Bmatrix}
\] 显然,这里有些错误。\(aa\) 这样的元素是不符合定义的。因为定义说必须要选择两个不同的元素(集合中本来也不应该有相同的元素)。所以\(aa,bb,cc\) 都是应该被去掉的。我们现在想要添加的过滤规则是:只保留每种字母出现一次的元素。因此,我们需要重新选择整理和组织元素形成图的方式以便计数。
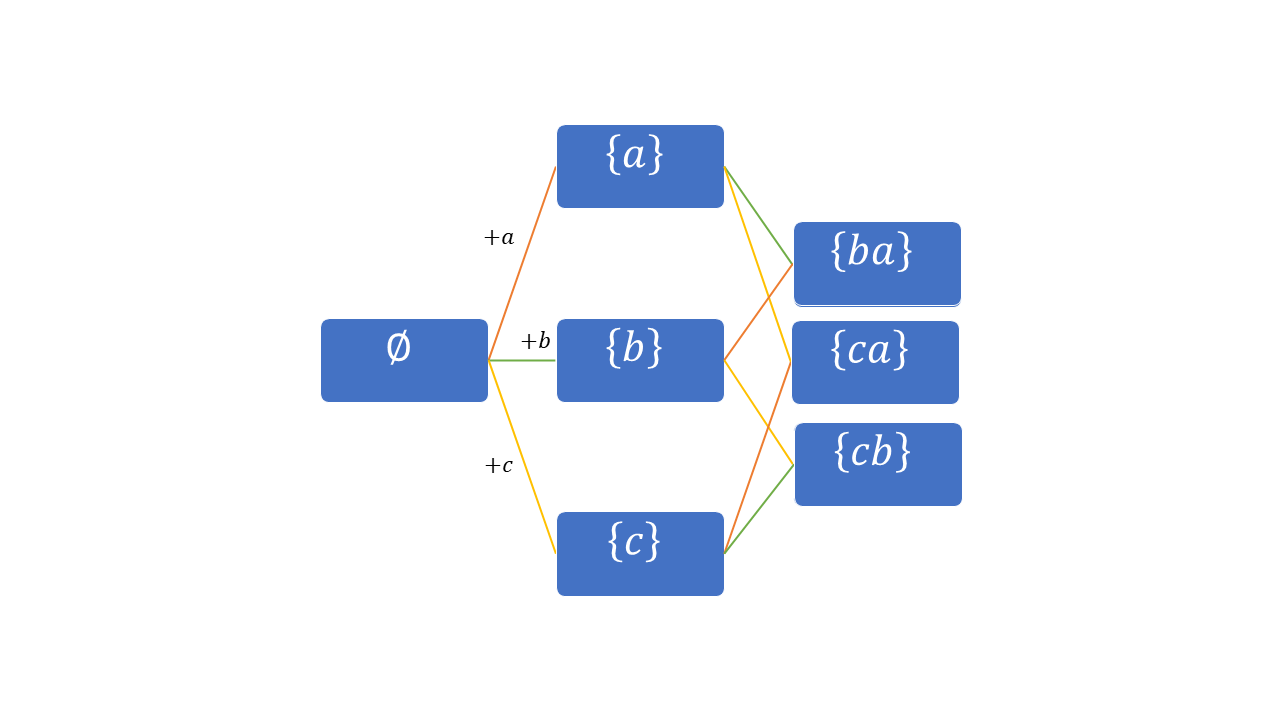
有时,退回一步思考常常能够给你思路。我们先假设对于一种元素可以选择多次,然后尝试把写出\(B\) 中元素的过程用图表达,因为这个过程不就是把\(B\) 中的元素遍历了一遍吗?我们在图中要经历的过程就是「写出\(B\) 中的一个元素」,而每个节点就是这个过程的一个状态,有向线段是状态之间的转换方式。最终结果如图1.
图1
在这张图上,我用不同的颜色标出了三种有向线段。对于状态我采用了集合的方式表示,不过依据定义,我们要区分\(\begin{Bmatrix} a,b \end{Bmatrix}\) 和\(\begin{Bmatrix} b,a \end{Bmatrix}\) . 无论如何,我们能明白它的含义就行。像这样的具有层次结构的图,我们称为「树」。节点就好比树叶,线段就好比枝干。我们可以用分类的方法整理\(B\) 。在图中,我们把它分成了三类,分类依据则是第一个元素。那么我们就可以把各个分类的元素数量计算出来,然后直接加起来就是最终结果。这就是加法原理。不过我们发现,每个节点都有固定的模式,除了最右边的节点以外,每个节点都与下一层的三个节点连接。所以我们想说的是,这几类的元素个数都一样,都为3. 我们只要把类的个数乘3就可以得到结果,这就是乘法原理。也就是 \[
\begin{equation*}
3\times 3=3^{2}
\end{equation*}
\] 我们也得出了对于第\(n\) 层,节点个数是:\(3^{n-1}\) . 那么再扩展一些,对于有\(m\) 个元素的集合\(A\) ,这个图的第\(n\) 层,节点个数是:\(m^{n-1}\) .
不过我们还没有满足「不能重复」这一条件。我们考虑一个例子,你已经遍历到了这颗树第二层上的\(\begin{Bmatrix} b \end{Bmatrix}\) 节点。你接下来要依据\([ +a]\rightarrow [ +b]\rightarrow [ +c]\) 这样的顺序遍历你对当前状态的操作并得出下一个状态。那么什么时候会造成重复呢?自然就是你遍历到的操作添加了你状态中已有的元素。对于有\(m\) 个元素的集合\(A\) ,当你遍历到第\(n\) 层时,依据定义,层数就是你做的操作的次数,所以你的状态就是已经选择了集合\(A\) 中的\(n-1\) 个元素。那么你就会遍历出\(n-1\) 个出现重复的状态。因为对于第\(n\) 层中所有的状态都是如此,所以我们直接在每个算出的状态数中乘上\(\frac{m-( n-1)}{m}\) 就可以了。对于上面的例子来说就是: \[
\begin{equation*}
3 \times \frac{3-( 1-1)}{3} \times 3 \times \frac{3-( 2-1)}{3} = 3 \times 2 = 6
\end{equation*}
\] 我们也可以发现如果集合\(A= \begin{Bmatrix} a, b, c, d \end{Bmatrix}\) ,我们要按顺序选出其中不重复的三个元素有\(4\times 3\times 2\) 种情况。我们可以总结出,对于有\(m\) 个元素的集合\(A\) ,这个图的第\(n\) 层,节点个数是: \[
m\times ( m-1) \times ( m-2) \times \dotsc \times ( m-n+1)
\] 到这里,我们就解决了排列的基本问题。现在来考虑组合问题。我们只需要稍微修改一下前面对于集合\(B\) 的定义:我们把只有顺序不同的两个元素视为同一个元素。我们按照上面的方法画出集合\(B\) 中元素的形成过程。
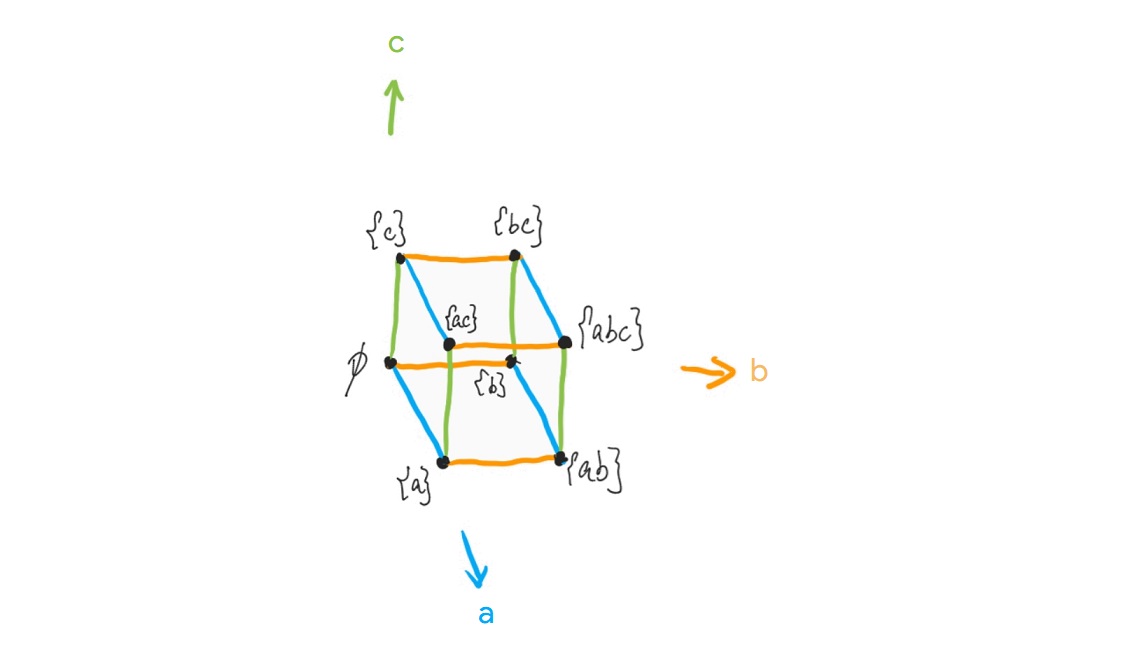
排列组合笔记3.png
这里我为了突出不考虑顺序这一点,删掉了集合内的逗号。要找出这张图的规律看起来很困难。于是我们想要找一个新的方法去组织状态和操作。你可能会想到,这时对于每个给定的状态,都可以唯一地对应简单的「选/不选」。比如说对于\(\begin{Bmatrix} a \end{Bmatrix}\) 这个状态,我们可以用\(\begin{Bmatrix} 1,0,0 \end{Bmatrix}\) 表示。也就是选A,不选B,不选C。这样做的优势在于哪里呢?它不但消除了先后次序所造成的差异,而且排除了选取多个相同元素的情况(当然,如果你想考虑这一点,也可以允许\((2,1,1)\) 这样的情况存在)。更重要的是,它提供了一个几何上整理上图中的节点的方法。\((1,0,0)\) 正好可以用三维直角坐标系中的一个点表示。重新整理后如下图所示。
图3
不难看出,对于有\(m\) 个元素的集合\(A\) ,我们可以用\(m\) 维的坐标系表示从集合\(A\) 中任意选取元素所得到的所有可能的状态,状态个数为\(2^m\) . 对于任意选取\(n\) 个元素到集合\(B\) ,我们可以怎么做呢?我们需要重新思考我们是怎样画出上面这张图的。
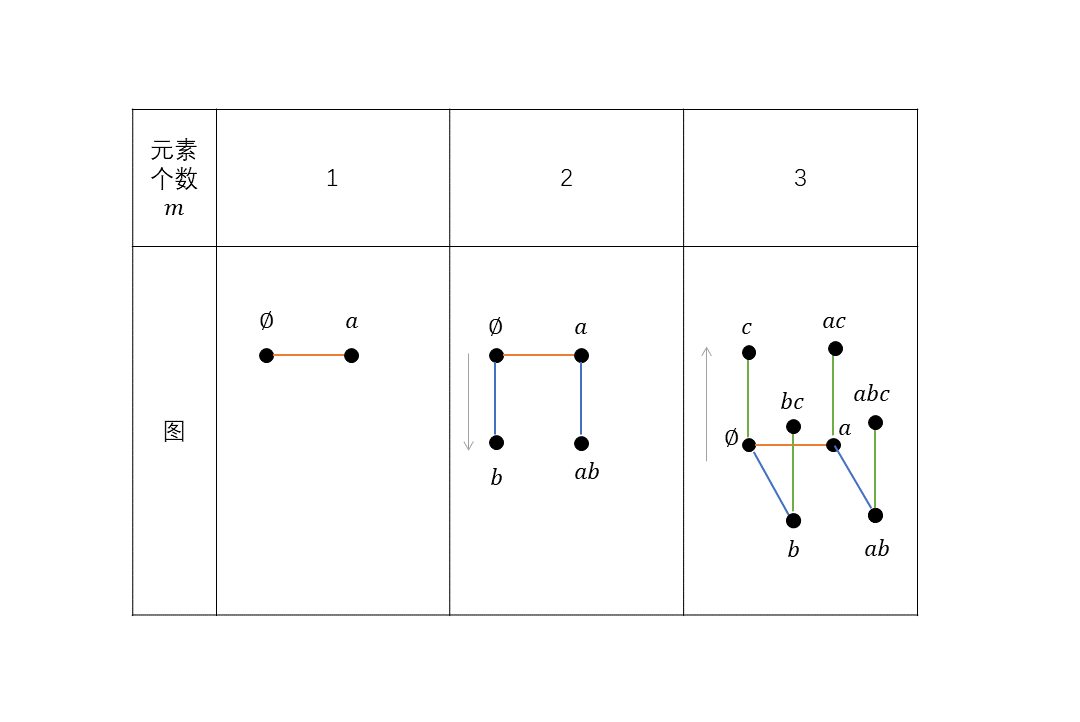
排列组合笔记4.png
为了讲清楚这一点,我又画出了三张图。它们分别对应元素个数为1、2、3时的情况。元素个数为0时只有一个点,就是$\(. 这里就不画了。注意图中的灰色箭头,它表示的是一个平移过程。例如\) m\(为2时,箭头表示向下平移,代表着增加\) b\(这个元素,从蓝色的线段也可以看出这一点。我们现在的目标是:找出当集合\) A\(中元素个数为\) m\(时有多少个包含\) n\(个元素的节点(这里\) n\(和上面的定义不一样)。在上面的例子中\) n$为2.
0
0
0, 1
0, 1, 1, 2
0, 1, 1, 2, 1, 2, 2, 3
1
1, 2
1, 2, 2, 3
1, 2, 2, 3, 2, 3, 3, 4
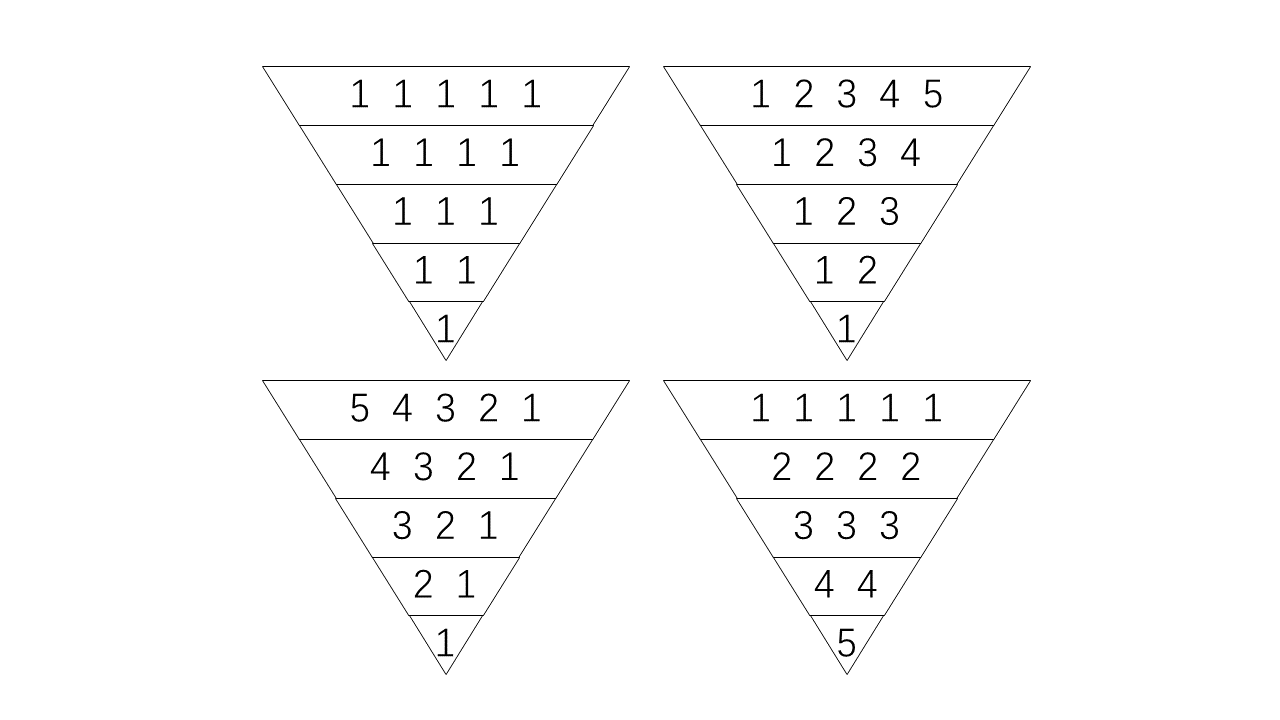
上面的这张表格的第一行是\(m\) 的值,第二行和第三行都是对应的图中的节点的元素个数。而第二行是由第一行「平移」得到的。举例来说,当\(m=2\) 时,第一行的0, 1代表着图中的\(\emptyset, a\) 而第二行的1, 2代表\(b, ab\) . 这正好对应了平移的操作。当我们想得到第\(m\) 列时,我们就把第\(m-1\) 列的第二行放在第一行的后面,然后整个放在第\(m\) 列的第一行。第二行则是对上一行的每个数字都+1得到的。我们再列出一个表格,写出每一列中各种数字的出现次数。
0
1
1
1
1
1
1
0
1
2
3
4
2
0
0
1
3
6
3
0
0
0
1
4
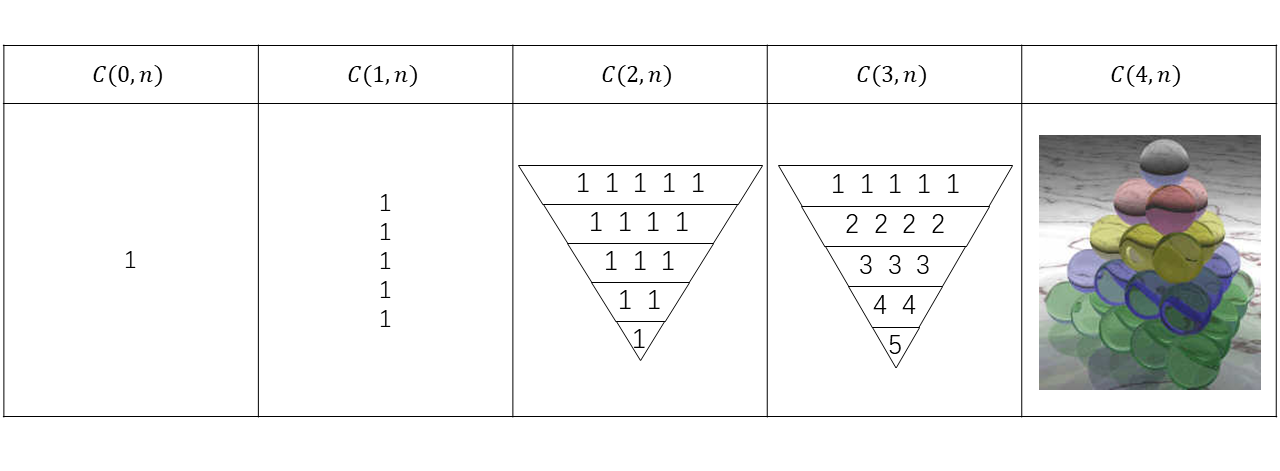
我们可以看出,「0」的个数是固定不变的,也就是说每张图中都有且仅有一个节点为\(\emptyset\) ,这是一切的开始。「1」的规律是什么?随着\(m\) 增加,它每次都加上1. 这是因为根据平移的规则,除了第一列的1以外所有的1都是由上一列的0加上1得来的,而每一列的0的个数都为1. 而2的规律也类似,它是由上一列的1加上1得到的。为了方便解释,我定义一个函数来给出这个表格中某一格的数字:\(C(m, n)\) ,\(m\) 表示的是表格的「数字」,\(n\) 表示的是第几张图(注意这里的和上面的是反的)。所以, \[
C(2, n)=C(2, n-1)+C(1, n-1)
\] 对于3 \[
C(3, n)=C(3, n-1)+C(2, n-1)
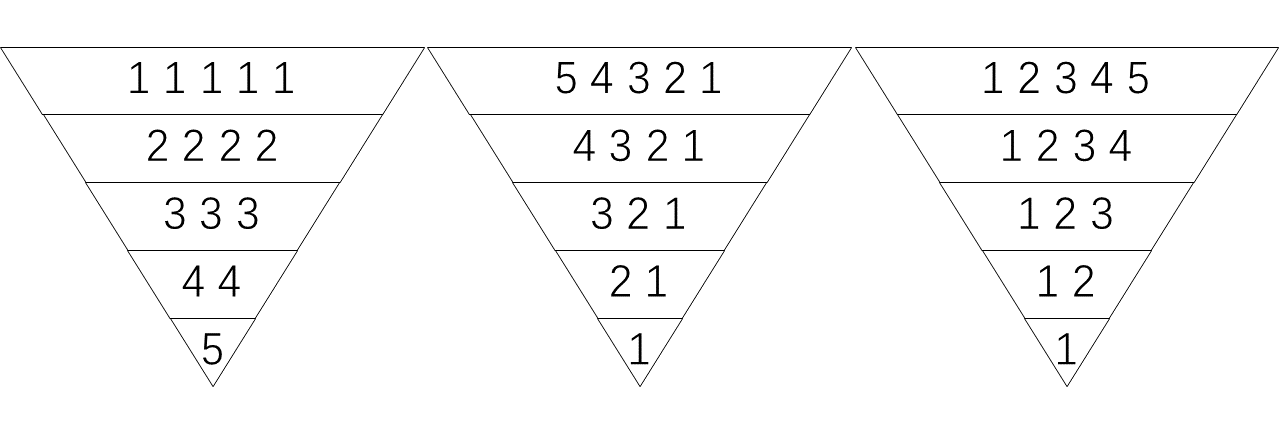
\] 如果你想要看看对于更大的\(m\) 是什么情形,你可以直接看「杨辉三角」:
杨辉三角
不过我们现在还是回到正题,我们先尝试写出\(C(2, n)\) 的规律,然后用它推出\(C(3, n)\) 的规律。
\(C(0,n)\) 1
1
1
1
1
\(C(1, n)\) 1
1+1
1+1+1
1+1+1+1
1+1+1+1+1
\(C(2, n)\) 0
0+1
0+1+2
0+1+2+3
0+1+2+3+4
\(C(3, n)\) 0
0
0+(0+1)
0+(0+1)+(0+1+2)
0+(0+1)+(0+1+2)+(0+1+2+3)
根据等差数列的求和公式,可以得到: \[
C( 2,n) =\frac{( 0+n-1) n}{2} =\frac{n( n-1)}{2}
\] 我们再仔细看一下: \[
C(3, 5) = 0+(0+1)+(0+1+2)+(0+1+2+3) = 0 \times 4+1 \times 3+2 \times 2+3 \times 1
\] 我们可以写出: \[
C(3, n) = 0(n-1) + 1(n-2) + 2(n-3) +\dots + (n-3)2 + (n-2)1
\]
注意到,去掉第一项后,这个式子是对称的!怎样去计算这个式子呢?我从计算平方和的方法中得到了灵感。为了演示,我选择\(C(3, 7)\) 进行计算。
排列组合笔记5.png
上图中有三个三角形,每个三角形中的全部数字加起来都等于\(C(3, 7)\) . 它是这样画的:第一行我们写下\((n-2)\) 个1,第二行写下\((n-3)\) 个2,以此类推,最后一行只有一个数字,就是\((n-2)\) . 你可以发现它们加起来就是上面的公式。然后我们把它旋转60°,一共旋转两次,就得到了上面的三个三角形。接下来,我们只要把这三个三角形中的数全部加起来除以3就是结果了。怎样去加这三个三角形?我们把相同位置的三个数加起来,放到一个新的三角形中。你可以看出,这个三角形中的数全都都是7. 详细的证明就省略了。而7的个数是:\(5+4+\dots +2+1\) . 这是一个等差数列。最终结果就是: \[
C( 3,\ 7) =\frac{( 5+1) 5}{2} \ \times 7\times \frac{1}{3}
\] 推广到对于\(n\) 来说: \[
C( 3,\ n) =\frac{( n-1)( n-2)}{2} \times n\times \frac{1}{3} =\frac{n( n-1)( n-2)}{3\times 2}
\]
那么,如果是\(C(4, n)\) 呢?问题开始变得复杂了。这次我们要用到正四面体。要对四面体数有个快速的了解,你可以看看四面体数序 。我们是如何排列我们的数字的呢?首先来看看我们要排列什么: \[
C(4, 8) = 1+[1+(1+2)]+\dots +[1+(1+2)+\dots+(1+\dots+5)]
\] 这里为了简单,我直接省略了所有的0. 我们现在要把数字填到下面这个四面体中,使它们相加等于\(C(4,7)\) .
四面体数
我在这里无法画出四个四面体。我只画出了四个四面体的底部,也就是上图绿色的部位。
排列组合笔记6.png
我们把这四个三角形的数都加起来,形成的新三角形中每一个数都是8. 这就是我们预期的结果。另外,每个四面体中有多少个数呢?仔细观察四面体,我们发现它的每一层的数字个数为1, 3, 6, 10, 15. 这正是刚才我们推出的数列\(C(3,n)\) . 这里一共有5层,所以\(C(3,7)\) 就是数字的个数。我们可以写出: \[
C( 4,\ 8) =C( 3,\ 7) \times 8\times \frac{1}{4} =\frac{7\times 6\times 5}{3\times 2} \times 8\times \frac{1}{4}
\] 推广后就是: \[
C( 4,\ n) =C( 3,\ n-1) \times n\times \frac{1}{4} =\frac{n( n-1)( n-2)( n-3)}{4\times 3\times 2}
\] 如果我们继续像这样推出\(C(5,n)\) 的话,我们就要讲到四维空间了。所以最好还是就此打住,回顾和比较我们已经发现的结论。
排列组合笔记7.png
这些解法之间都存在着一种固定的模式,而实际上这个模式就来源于定义。仔细观察表格,格内的所有数加起来,就是那一格的答案。不过这里有一点让人困惑:前3列中都只有一个数字,就是1,为什么到了第4列及之后,就开始有了1, 2, 3等等呢?其实,我们简化了\(C(3,n)\) 的写法。你如果集中精力,对照着最右边那张四面体数的图,想象你把\(C(3,n)\) 中大于1的数都展开成多个1,并且把这些多出来的1放置在四面体上,你会发现它们刚刚好能够填满四面体。也就是说,由数列1, 2, 3...组成的三角形数组都能用只由1组成的四面体数组表示。那么由数列1, 2, 3...组成的四面体数组能不能用三角形数组表示呢?是可以的,数列为1, 3, 6, 10...
现在,离最终的答案已经很近了。不过,我们还差一点。仔细观察刚才我们推出的两个普遍公式,我们似乎有一种感觉: \[
C( m,\ n) =C( m-1,\ n-1) \times n\times \frac{1}{m}
\] 我们应该好好思考一下这一条依据经验和直觉猜到的等式。对于大于4的\(m\) ,情形是很难想象的,所以我们还是列出这个式子: \[
C( 2,\ 5) =C( 1,\ 4) \times 5\times \frac{1}{2}
\] 它是在说什么呢?代入刚才的思路,我们应该猜到\(C(2, 5)\) 被写成\(1+2+3+4\) . 而再倒序一下就是\(4+3+2+1\) . 这两个式子上下放在一起,把对应位置的数相加就是\(5+5+5+5\) . 之后再除2就是答案了。我们似乎可以捕捉到这个思路的结构:假设你现在要算\(C(m,n)\) ,你就把\(C(m,n)\) 整理成好几组数的和,每一组中的所有数字都是同一个。
(至于具体的证明实在想不到了...)
最后,我还想简单介绍一下「乘法原理」。(这里直接用教材的写法了,\(A^{3}_{5}\) 表示5个中不重复地排列3个) \[
A^{3}_{5} =5\times 4\times 3=A^{1}_{5} \times A^{1}_{4} \times A^{1}_{3}
\] 可以发现, \[
A^{1}_{5} \times A^{1}_{4}
\] 在这里对应的含义就是对于树状图的第二层中的每个元素,都有\(A^{1}_{4}\) 个线段连接到下一层的元素。而这个意思正是「5个中选一个,再在4个中选一个,再在3个中选一个」。也就是教材上的定义方法。
可以在此基础上稍微扩展,形成「除法原理」。也就是对于树状图的某一层中,有\(\frac{1}{n}\) 个线段连接到下一层的元素。而这个说法听起来就很微妙了。我个人猜测这个说法在引入概率之后是可以被合理化的,不过我还没想出来。
Reference:
后记:
这篇文章是我在学习排列组合时自己找了些资料,经过理解和整合后呈现的结果。不过,后面这一部分基本都是我自己想到的。有些人会说,我这样的理解太复杂冗长了。确实是这样,在教材中这些知识都有一些更加简单直观的解读。但是我认为,对数学的探索并不只是为了解决问题本身,更重要的是发现各个知识之间的联系。我们刚才已经触及到了排列组合之外的很多东西:图和树、杨辉三角、三角形数、四面体数等等。我们不应满足于一个基于常识的对数学概念的解读,因为常识总是容易出错,而且常识与常识之间是零散的。所以,我更加愿意花一些时间,寻找常识背后的完整逻辑。这大概就是本文的意义所在了。
经友人指点,我在讲解组合的时候画出的图对应数学上的一个概念「Abstract polytope」 (抽象多胞形)。如果你有兴趣的话,可以去维基百科上看看。